

同人活动也是一种制品。
传统经济学假设买卖双方全知全能,因此同一种商品在市场上只会有一个价格。但显然不可能买卖双方都是全知全能的,这个假设过于孱弱以至于持久被诟病。因此乔治·斯蒂格勒(George Stigler)提出了很有洞见的模型建构。
Stigler (1961) The Economics of Information 的核心论点是:信息是有成本的经济品。消费者进行最优搜寻——当额外一次搜寻的边际成本等于其带来的边际收益时停止搜寻。
在同人圈里,经常存在这样的体验。满怀期待地预售下单或者参与拼团,等了几个月拿到制品,结果一看,不太符合自己的要求。部分同人制品呈现出消费前无法完全评估质量,只有拿到实物后才能判断的特征。例如同人刊物,同人音乐专辑,同人活动门票,预售拼团的谷子。这与Phillip Jacob Nelson (1970) 所定义的经验品(experience goods)本质类似——消费前无法确切知道质量,所以这是一种薛定谔的猫。
说到薛定谔的猫,它属于服从某种概率分布的随机变量,那么面对未知信息,我们也可以这样建模。传统的建模一般假设商品的预期呈现为正态分布,这个先验假设一般存在于标准商品市场。但是基于亚文化的商品市场存在高度的无标度网络特性,这个特性来自于当前社交网络算法的统计平均——大量默默无闻的信息终端和少量高度连结的信息节点。无标度网络通常对应的是幂律分布,而并非传统的正态分布。
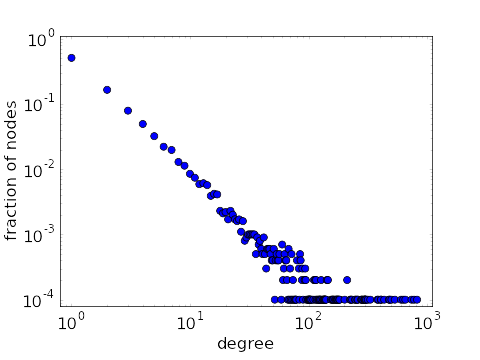
典型的幂律分布
假设如果我们将同人制品带给读者的效用 设定为服从帕累托分布(一种典型的幂律分布),其概率密度函数可以表示为:
所有消费者应当都存在一个预期阈值 。
一般聪明的消费者认为只有当预期制品的质量 时,才会下单;否则,TA们会继续花时间(支付成本 )去寻找下一个合适的制品。
我们用积分公式来表示这个平衡:
一般来讲作为同人商品来说,我们的信息搜寻成本虽然高度取决于时间闲暇,但是其本身存在硬属性——我今日不消费和明日不消费,不影响我吃饭(非必需品性质),因此我们认为普遍存在愿意花心思找到符合自己要求制品的消费者。这个平衡确实能得到如下结论:
- 搜寻成本 越高,吃粮阈值 就越低。 如果现实太忙( 极大),根本没时间去仔细扒试阅、等返图。这时候,为了能吃到制品就只能妥协,降低自己的底线
- 质量方差 越大,搜寻的潜在收益越高。 如果质量参差不齐到了极点,哪怕多花点时间(承担搜寻成本)也是值得的,因为一旦淘到神仙制品,对自己的精神满足是巨大的。
在概率论中,这个积分可以通过分部积分法简化为对尾部概率的积分:
我们定义 是市场上的最低商品质量下限
现在,我们将帕累托分布的 ,其中 为 其累积分布函数(CDF),即质量小于某个值 的概率为:
代入这个极简公式:
假设 (保证均值存在),我们解开这个积分:
因为,当 时,。因此:
我们把目标变量 提取出来:
两边同时取 次方,得到最终的帕累托-斯蒂格勒搜寻均衡解:
假设存在一个极高的审美阈值
预期搜寻次数 服从几何分布的倒数:
因为审美阈值 被拉得极高,预期搜寻次数 会呈指数级爆炸。大多数人在有限时间闲暇内,为了满足自己的精神消费需求,则会选择包容创作者,适度降低审美阈值。
幂律分布适用于成规模的市场
显然,同人市场规模越大,消费者搜索的成本也就越高。 同时,由于亚文化符号传播高度依赖社交网络算法,而社交网络通常呈现无标度特征。结合无标度网络理论,高昂的搜寻成本容易迫使消费者采取启发式搜索(如依赖榜单)甚至是被动推送,这种行为在宏观网络拓扑上直接表现为优先连接,即,新来的节点在选择连接对象时,并非随机选择,而是倾向于连接那些已经拥有很多连接的节点。
如果同人内容生产者的内容不符合算法选择,制品信息就会被归纳为网络里的边缘节点,其连边数 长期趋近于 0,因为算法和读者的高搜寻成本切断了边缘节点被发现的路径。
根据帕累托指数 与网络度指数 的不同,一般可以分为两类社群。同时,根据社区规模和网络演化阶段的不同,同人社区的网络拓扑结构会发生根本性的相变。
中大型社区:标准无标度网络
这类社区存在核心主导节点,同时也分布着多个次级中心节点。 消费者以降低成本的启发式搜索为主,但由于随机淘金带来的高潜在收益,仍会保留极小比例的随机搜寻作为“风险投资”。
创作者存在一定流动性。新人若能通过局部范围的相互推荐(如小团体的密集推荐)越过传播阈值,即可触发全局优先连接,跃迁为网络的次级中心。
微型/冷门社区
这类社区可能缺乏网络节点的持续增长机制或处于早期阶段,且信息总量未达到过载状态。优先连接机制失效,无标度网络退化为随机网络(Erdős-Rényi Model)甚至全连接图。这种社区内,消费者直接采取穷举搜寻策略即可遍历所有作者,拥有丰富额的信息量。在这类社区中,可以用均匀分布来作为先验衡量。
声誉是信息市场中的劣等品(下位替代)
声誉一般认为是创作者的一种积累,来自于过往创作者在社区里抛头露面积累的声望,属于社区受众的潜在共识。
我们可以认为同人市场是信息高度不完全的,毕竟有一部分同人制品作为经验品在购买前是看不透的(比如本子,音乐专辑,或者预售的谷子)。看到的同人宣发,只是一个信号,记作。信号是不完美的,它也有噪音。
这时候,消费者经常会做贝叶斯决策更新。一般我们对制品作者的先验预期是 (也就是我们根据历史消费和对市场的朴素观察得到的声誉),其确定性由方差 决定。看完宣发后,消费者对制品的后验预期质量 会变成两者加权平均:
权重系数 取决于作者声誉的可靠程度与试阅信号的可靠程度的对比:
(其中 是试阅信号的误差方差, 是先验声誉的误差方差)
在微观经济学中,劣等品的严格数学定义是:随着消费者“收入”的增加,对该商品的需求量反而下降(即需求收入弹性为负)。 在信息市场中,我们定义 闲暇资源(): 消费者的信息预算或时间财富。这与搜寻的机会成本 成反比()。时间越充裕(如学生党), 越高;时间越昂贵(如工作党), 越低。 搜寻努力(): 消费者投入到解读宣发信号 上的精力。显然, 是信息财富 的增函数:。
根据微积分的链式法则,我们求贝叶斯更新的权重 对 的偏导数:
容易得到
因此随着消费者信息财富 的增加(即时间充裕、搜寻成本 降低),他们对声誉 的权重 呈严格递减趋势。声誉在数学上完全符合“劣等品”的统一定义。
通俗来讲,信息不透明的情况下,先相信大家说的东西,比较合理。
方差无穷大的诅咒
如果在中大型社区的无标度网络中,帕累托指数小于2,则方差会变得无穷大。这体现在极端的市场中,无论是闲暇多还是闲暇少的消费者,其面临的客观搜寻成本都远超同人本的预期收益。
如果方差无穷大 ,则:
易得这类权重退化为常数1,即所有的后验预期质量全部取决于前期观察到的声誉。
如果 是常数, 就会导致上一个章节的,也就意味着时间闲暇禀赋的效应完全消失。在这里我们无法通过有限的精力辨别真实,无论个人的搜寻能力多么强大,都无法保证自己能一定满足自己的期望阈值 。因此在这个情况下,消费者的最优策略是:当且仅当声誉先验的信号精度高于随机猜测时,依赖声誉做出购买决策。 毕竟消费者不用每次购买都从零开始搜寻,他们天然存在路径依赖,并且在无标度网络效应严重的社区,路径依赖越严重。
为什么大家依赖声誉

研究信号传播也是一个很有意思的过程。A. Micheal Spence 因此获得了2001年的诺贝尔经济学奖。
假设目前市场仍然存在有效信息传播,且没有外部信息算法选择的干扰。我们可以使用Spence (1971)提出的模型,这是一种动态不完全信息博弈模型。该模型核心在于信息优势方通过采取可观察的行动向信息劣势方传递真实信息,以降低信息不对称,从而实现双方的效用最大化。
我们设定市场上存在两类创作者,其真实质量类型为 ,分别代表客观偏高质量和客观偏低质量。
市场知道符合群体喜好的创作者的先验概率为 ,但无法直接观测特定个体的 。在极端的市场噪音下,若创作者不发送任何额外信号,或者发送无成本信号,消费者将根据期望给出一个极低的保留价格(或者根本不达成交易,只是看看),新人收益趋近于基准线 。
为了向消费者证明自身类型 ,创作者必须选择发送一个可观测的信号量 。在同人市场中, 代表一种不可回收的沉没成本,例如投入大量时间进行严苛的考据并公开笔记,大力投入金钱时间在宣发上。
我们引入成本函数 。在传统的市场中,成本 纯粹是对资源的消耗,它带来的是负效用。但在同人市场生态中,创作者投入极大精力的过程本身,有时能产生巨大的内在情绪收益。
该模型成立的绝对核心假设,是单交叉条件(Single-Crossing Property),即发送相同单位信号的边际成本,低质类型严格大于高质类型:
这个不等式可以看出在这个条件下客观偏低质量想要把自己伪装成很牛逼创作的行为,其实是要比高质量的创作者成本高的。
假设市场观测到信号 后,相信创作者是 类型,并愿意给予高回报。我们可以认为存在能够让市场敢于信任的均衡点 。
首先,对于低质量创作者 ,伪造信号 伪装成高质量创作者的收益,必须严格小于他什么都不做、直接接受他本来创作应得的收益:
即 。这规定了信号量 的下界
其次,对于高质量创作者 ,发送信号 的净收益,必须大于被埋没的收益:
即 。这规定了信号量 的上界:自证清白的成本不能高到使得高质量创作者也面临亏损。
将两者联立,我们得到了分离均衡存在的数学区间:
但如果加入情绪收益补偿后,情况发生了变化。假设市场中存在大量客观质量还在起步阶段,但处于极度狂热状态的新人创作者,由于其极高的表达欲,其边际热情补偿极大。
此时,对于狂热新人而言,由于内在效用的强力对冲,其感知的边际净成本会发生暴跌:
花了大量精力做精美宣发的人,可能是真正的高质量神仙 ,也可能是仅仅凭借一腔热血但内容空洞的狂热者 。因此信号 缺乏传递真实类型 的信息。导致经验上消费者更依赖于声誉。当然,如前文所述,只要信息是确定的,大家会忽略声誉这个下位替代品。
创作者该如何看待声誉和信息
将视线从单期的博弈拉长到多期博弈。设时间节点为 。在 期,作为没有任何先验数据的新人,市场对其实际类型 的先验信念极低,记作初始声誉 。为了打破这个僵局,创作者被迫支付了极其高昂的沉没成本 来发送强信号。
当这个条件达成,市场的贝叶斯更新机制被强行重启。由高昂成本换来的后验概率直接成为了下一期博弈的先验声誉。对于新人而言,前期发送 所承受的巨大成本,其实都能转化为回报。
因此只要大家认可了创作者,创作者就能稳稳扎根。因此某种意义上,如果声誉一直都在稳步积累,先来者优势是巨大的。
在同人社区的早期阶段,内容总量有限。在这个时期,产出一篇结构完整的短篇,或者几张完成度尚可的线稿,或者制作一些一看就很漂亮的谷子,就足以向市场发送清晰的 类型信号,从而低成本地完成初始声誉的原始积累。
不过,随着时间推移,市场容易转向柠檬市场。低质量类型大量涌入,且批量制造虚假信号的边际成本不断趋近于零。最重要的例子就是AI创作的泛滥。要让消费者确信创作者不是AI生成的废图或者量产文,后发者被迫支付的信号阈值将发生指数级的通货膨胀。
此时,先发者与后发者处于完全不对等的博弈位面,先发者的声誉强,所以大家在信息不完全的情况下偏好于先发者。当然,整体来说由于同人创作者对于收益的不敏感性,即它作为生产者的目的是最大化热情周期,最重要的事情其实是可以吸收声誉伴生的精神满足回馈,因此柠檬市场效应并不会如传统分析里那样严重。
根据前文的分析,信息完全的情况下,声誉将会被作为下位替代品。因此同人创作者一方面可以积累自己的声誉,另一方面尽量保持自己制品信息的透明度,降低消费者选择的不确定性,因此谜语人式的宣发不一定让人讨喜。