
建立“通用时间序列模型”:巴别塔之梦是否能实现
在 ChatGPT 引爆了 NLP 领域的“基础模型”狂潮后,时间序列预测(Time Series Forecasting)领域也陷入了一种集体焦虑。不管是学术界还是工业界,都在试图复刻这一路径:收集海量的金融、气象、电力、医疗数据,试图训练出一个能通吃所有下游任务的通用模型。
最近有幸参加学校的暑期研究项目,从2022年开始,我就对时间序列有了兴趣,只是当时是偏向经济金融的时间序列,这次是一个偏向应用的建模。
基于我近期在电网负荷预测中的研究与实验,我也研读了这个领域不少的论文,我发现两个问题。
大多数论文的Setting比较有一个很有意思的指标,基于不同数据集的表现,但是一个模型真的能泛化到异构性很高的数据集吗。我们可以思考,金融数据集,一个信噪比很低的数据集,和电力数据集,一个周期性很强的数据集,在这种异质性的情况下,比较同一个模型的表现,是不是有点有失偏颇。
Transformer是否真的比Linear模型更有效?这一点Dlinear的作者(2023)已经提出了疑问,这里就不再过多赘述。但是有另一个问题,大多数模型都在试图用单变量预测单变量,并且还有一个Setting是利用96步的回溯窗口预测未来远大于96步的部分。我们如何知道模型不是因为信息量过少在瞎猜。这些似乎都是一个争论性的话题。
一、 语义的陷阱:Token 的本质差异
在 NLP 中,Token 是有“语义锚点”的。单词 “Apple” 无论出现在莎士比亚的诗句里,还是在乔布斯的传记里,它都指向一个相对稳定的语义空间。因此,Transformer 的注意力机制可以有效地捕捉上下文关联。因此,Google的CBOW模型作为大语言模型的前置也就应运而生。
CBOW 模型,使用上下文关联来修正Token的嵌入,使其捕捉上下文语义
但在时间序列中,我们面对的是什么?
一个浮点数 24.5。
如果在气象数据中,它可能是气温;在电力数据中,它可能是发电量;在金融数据中,它可能是股价。
目前的通用模型试图通过 Patching 技术(如 PatchTST)将一段子序列视为 Token 。然而,这种 Patching 仅仅解决了输入维度的问题,却丢失了语义语境。标准 Patching 技术将时间序列切片处理为匿名 Token,导致了语义上下文的丢失(例如,无法区分“周一早晨”的切片与“周日傍晚”的切片)。
对于不同的数据集来说,数据点(或者说数据点的Patch),如果能够语义化嵌入到隐空间,其实是一个很有意思的举措,我也看到近期有论文这么做,但是从个人的理解上来看,语义化本身也是让模型理解数据背后的物理或者背景现实意义,以做出更有靶向性的输出,但是这个过程是不是可以通过一个物理感知的过程去实现呢?
二、单变量时序预测注定是“不完备”的
在过去的一两年里,时间序列预测领域出现了一个奇怪的现象。
以 PatchTST 和 DLinear 为代表的各类通用SOTA模型横扫了顶会。有趣的是,它们的核心策略是Channel Independence (CI),即把多变量数据强行拆解成多个单变量序列,独立预测,最后再拼起来。
我对这种现象深感不安,这种对多变量(Multivariate)模型的系统性忽视,实际上有点危险,好比,我们在开车时只看后视镜,而不看挡风玻璃外的路况,我们真的能开好车吗?
单变量预测的数学硬伤:信息不完备性
单变量预测的核心假设是:系统的未来状态完全蕴含在其过去的状态中。
即 。
在封闭系统中,这或许成立。但在现实世界的开放系统(如电力、金融、交通)中,这是一个巨大的谬误。
以电力负荷为例,负荷的变化不仅仅是人类活动惯性的延续,它在很大程度上是由外部冲击驱动的。
最典型的就是 “鸭子曲线”(Duck Curve) 。 当正午阳光强烈时,屋顶光伏发电量激增,导致净负荷曲线突然出现一个深坑;而当云层飘过或日落时,负荷又会瞬间反弹。
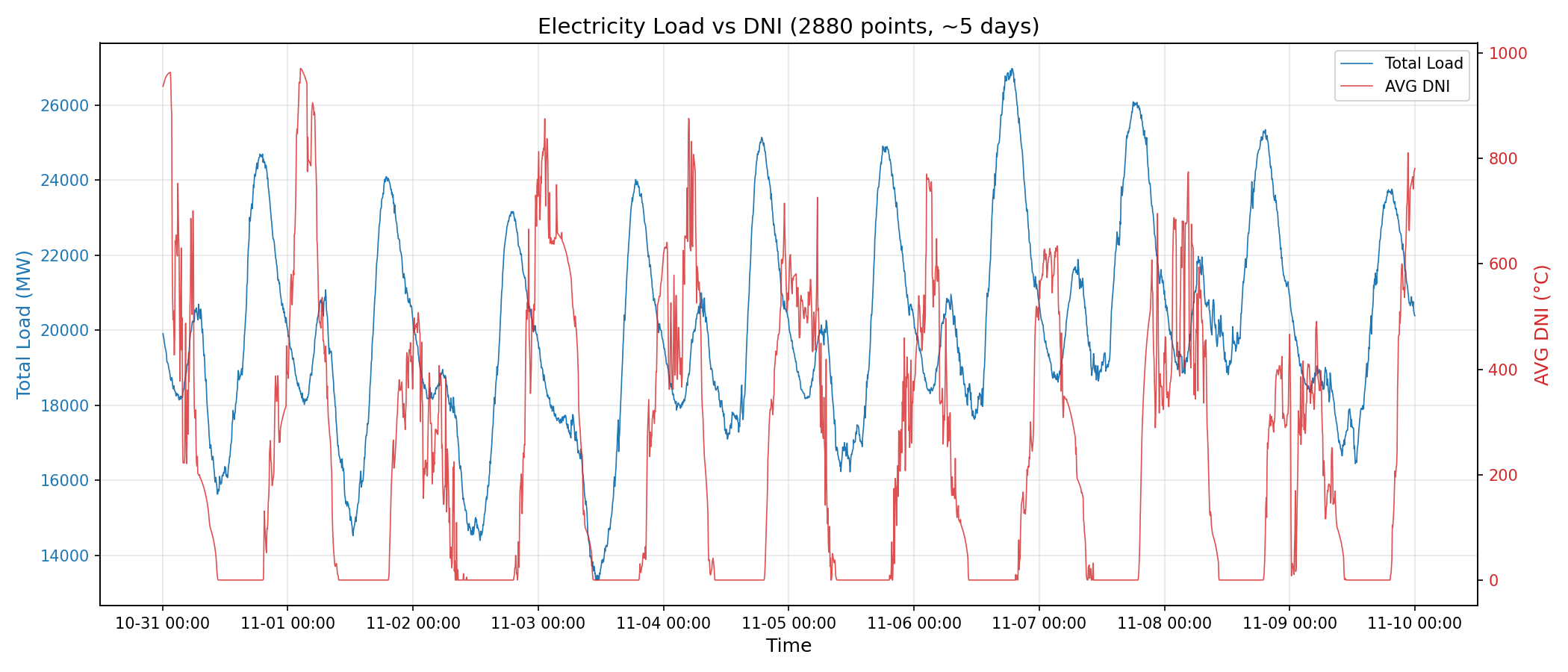
鸭子曲线和辐照度的曲线叠加图,可以观察到直接的因果
在这个例子中,太阳辐照度(Irradiance)是一个关键的外部协变量。如果模型只有负荷的历史数据,而没有辐照度数据,那么在数学上,它的信息集就是不完备的。 在追求一个量化关系时,我们过去的数据无法指导未来(这点很显然),因此如果想要在这部分提升精度的话,没有协变量的参与,就不太可能做到。
很多论文认为非Channel Independence的做法会引入噪声。但我认为,根本原因在于我们对多变量的处理方式太粗糙了。
目前的标准做法是:把时间、天气、负荷全部做个 Embedding,然后丢进同一个 Self-Attention 层里一锅乱炖。
这在数学上是非常不严谨的,因为这些变量属于完全不同性质的流形
比如“小时”、“星期”、“节假日” 。 这些变量是先验已知的。我们不需要“预测”明天是周几,这是硬约束。它们构成了时间序列的骨架。而“气温”、“湿度”、“降雨量” 。 这些变量服从某种概率分布,且往往具有复杂的物理特性。
传统Transformer对于隐状态的Concatenation——一锅乱炖
三、物理感知是时序预测罗盘
现在的研究有一种倾向,认为只要数据量够大,模型就能学会一切。于是我们看到了大量忽略领域知识、盲目堆砌算力的“黑盒”模型。但是时间序列不一样,只在一个维度上看,单纯的数据驱动模型,在面对未曾见过的极端情况的时候,总是会表现不佳。
当试图用深度神经网络去拟合一个复杂的物理系统(如电力负荷、流体动力学或气候变化)时,我们实际上是在高维观测空间 中,试图恢复一个低维的流形 。 对于一个盲目的数据驱动模型,它没有流形的全局几何先验。在一些稀疏区域(例如金融极端的暴跌,极端天气引起的电网中断),模型只能依据局部曲率盲目延伸。 一旦遇到流形曲率剧烈变化的区域往往会直接跳出流形切空间,而无法确定学习的结果是否正确。
物理感知的本质,是在高维空间中引入了约束方程。在复杂系统科学中,迪迪埃·索内特(Didier Sornette)提出过 LPPL(对数周期幂律)模型。它通过描述系统的“超指数增长”和“加速震荡”,成功预测了多次金融泡沫的破裂断裂。 LPPL 的核心洞见在于,复杂系统的突变,从来不是随机漫步(Random Walk)的结果,而是正反馈机制导致的“有限时间奇点”。(当然从重整化群的角度来说,泡沫的特征就是它的局部结构是自相似的,这点可以参考文章 The Bitcoin Crash and How Nature Works)
当前的主流时间序列模型(如 iTransformer, PatchTST)在处理这些问题时,却犯了一个根本性的错误:它们假设系统是平稳或线性外推的。它们看不见那个即将到来的临界时间点。不可避免地,有一部分时间序列数据集,存在一个外部变量引起的超指数增长的过程(不管它有没有发生,系统都可能出现这个过程),单纯的单变量模型无法理解这种物理上的正反馈,因为他们缺乏对于因果变量的感知和约束。
从约束上来看,时间特征(小时、星期)不是普通的变量,它们是流形的参数化坐标。通过一些技巧,我们可以将流形 强行绑定在一个固定的拓扑骨架上。 这意味着,无论某些局域数据多么稀疏,模型都知道“周一早上八点”和“周一晚上八点”在流形上不仅是距离遥远的点,而且处于不同的拓扑分支上。这种硬编码的坐标系防止了模型在稀疏区域发生拓扑粘连。从这点来讲,基于RNN的模型反而比Transformer更有优势,因为RNN天生地在隐空间上有一个序列偏好。
从消融学习上来看,对比有时间编码语义嵌入和没有的情况,模型不仅在总体指标上,而且在局部也有一些高度的提升。
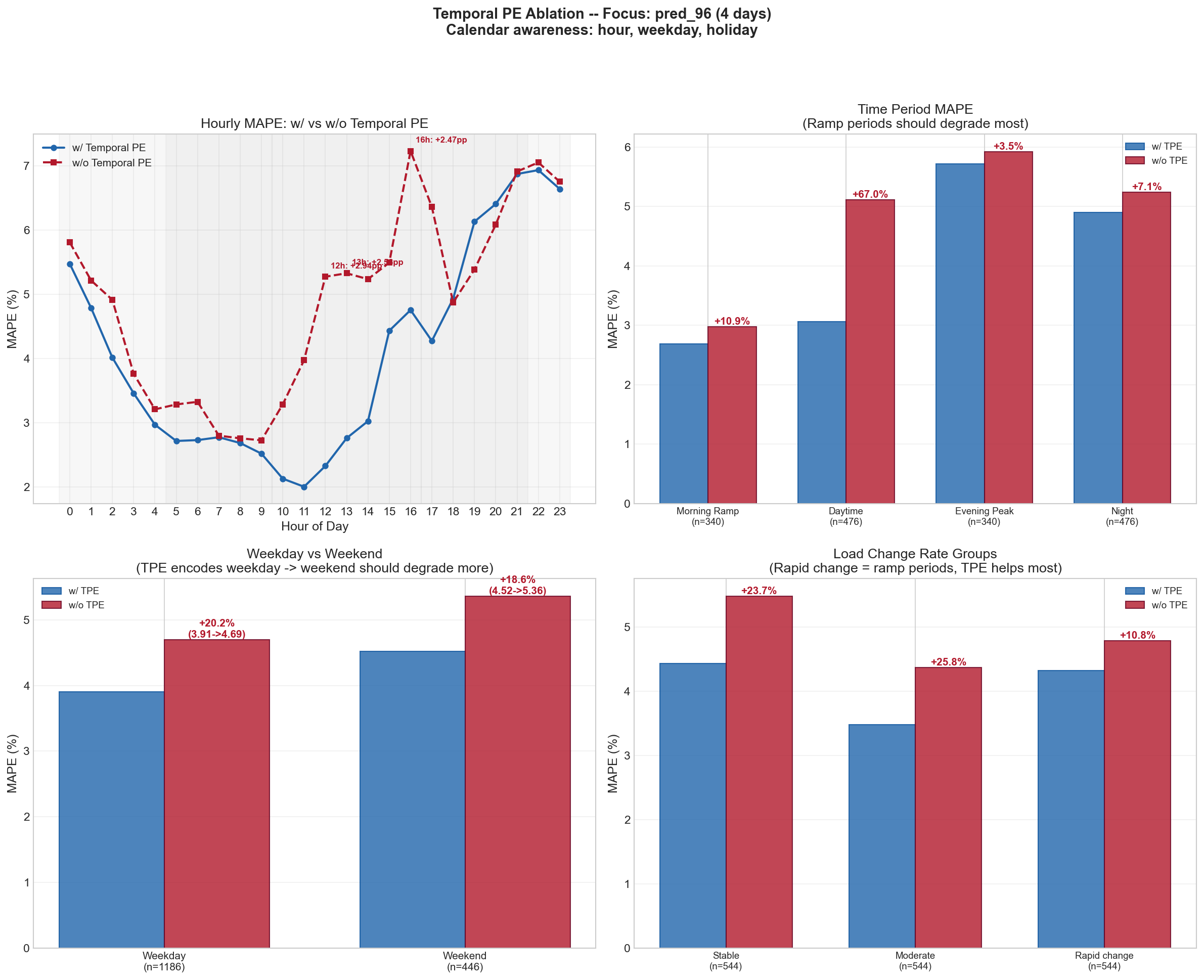
如何在“惯性”与“冲击”之间寻找平衡点?
在时间序列预测的建模哲学中,存在着一个永恒的博弈——到底我们应该相信系统的惯性,还是相信外部的冲击?
有人认为认为历史会重演。今天的数据很大程度上取决于昨天的负荷。当然也有人认为外部的约束条件决定一切。如果明天石油危机爆发了,油价必然飙升,不管昨天发生了什么。
绝大多数物理系统都有“惯性”。在电力系统中,这种惯性表现为人类活动的周期性:日出而作,日落而息。在动力学中,这可以被称为极限环(Limit Cycle)。
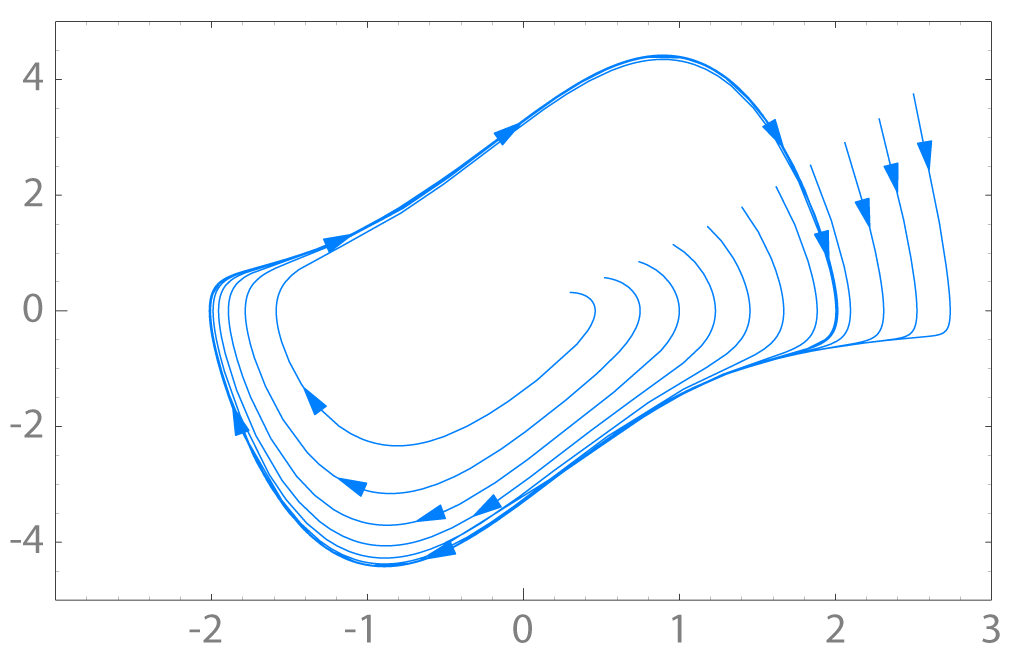
稳定极限环以及相应的庞加莱映射 作者 User
at English Wikipedia,CC BY 2.5,https://commons.wikimedia.org/w/index.php?curid=732841
从流形的角度来说,在传统的时间序列流形(仅由历史负荷 构成)上,距离通常被定义为时间步的邻近度。
在这个流形上,测地线(Geodesic)代表着系统的惯性或平滑演化。相空间的极限环对应的是流形的测地线。
但,现实世界不是封闭的。
当黑天鹅事件来袭,系统不再遵循简单的周期运动。它进入了一种混沌状态。在这个状态下,两个极其微小的协变量初始差异(比如气温 35°C 和 35.5°C),随着时间的推移,会导致电力负荷曲线的轨迹在远期来看发生巨大变化。如果只有单变量数据去预测一个非常长期的窗口,模型可能直接退化成了一个随机游走的状态,因为没有足够多的信息让模型学习。
协变量可能修补了流形的拓扑结构
如果是光滑的流形(如极限环),我们只需要历史数据就能无限预测下去。事实上一些周期性数据确实很不错,如果求稳,我觉得XGBoost等集成学习的传统方法实际上在工业应用上还挺占优势的(实际上也是主流)。
但现实世界充满了奇异吸引子,它们是分形的,甚至是不连续的。
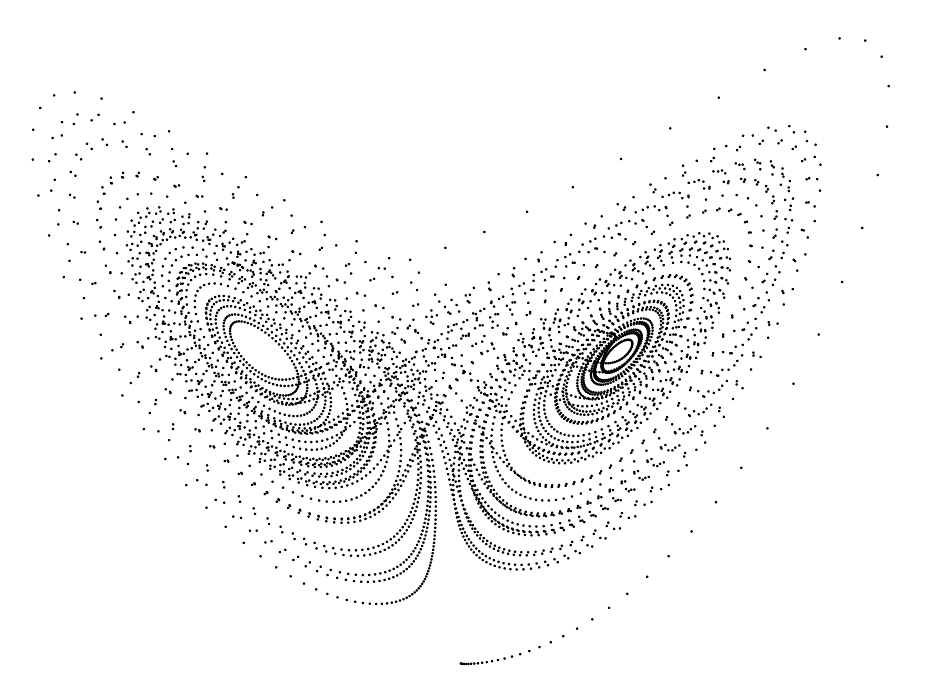
想象一下光伏发电导致的净电力负荷骤降,在相空间中表现为轨迹的突然坍缩。从几何上看,流形在这里发生了剧烈的弯曲甚至断裂。如果我们的模型能够观察到足够的信息(包含历史和未来的预测因果协变量信息),当系统运行到流形的断裂边缘,历史轨迹无路可走。此时,未来的可观察信号像一座桥,连接了流形的当前状态 和未来的状态 。
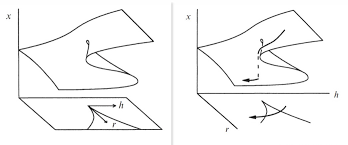
流形的一种突变
也就是为什么,让模型理解造成这个状态的因素很重要,例如模型能通过Cross Attention查询到历史上的任何征兆并且显式学习到,至少比瞎猜好用。 在 Attention 机制中,两个状态 和 之间的“距离”不再取决于它们在时间轴上离得有多近,而是取决于它们的 Query (未来协变量) 和 Key (历史协变量) 有多像:
这在几何上等价于引入了一个新的度量张量 :
(协变量部分): 由 Cross-Attention 引入。这是关键的修正。
这种新的度量距离可以修正测地线上的插值依赖,在类似图上的突变点找到新的演化方向。
四、超越Transformer?
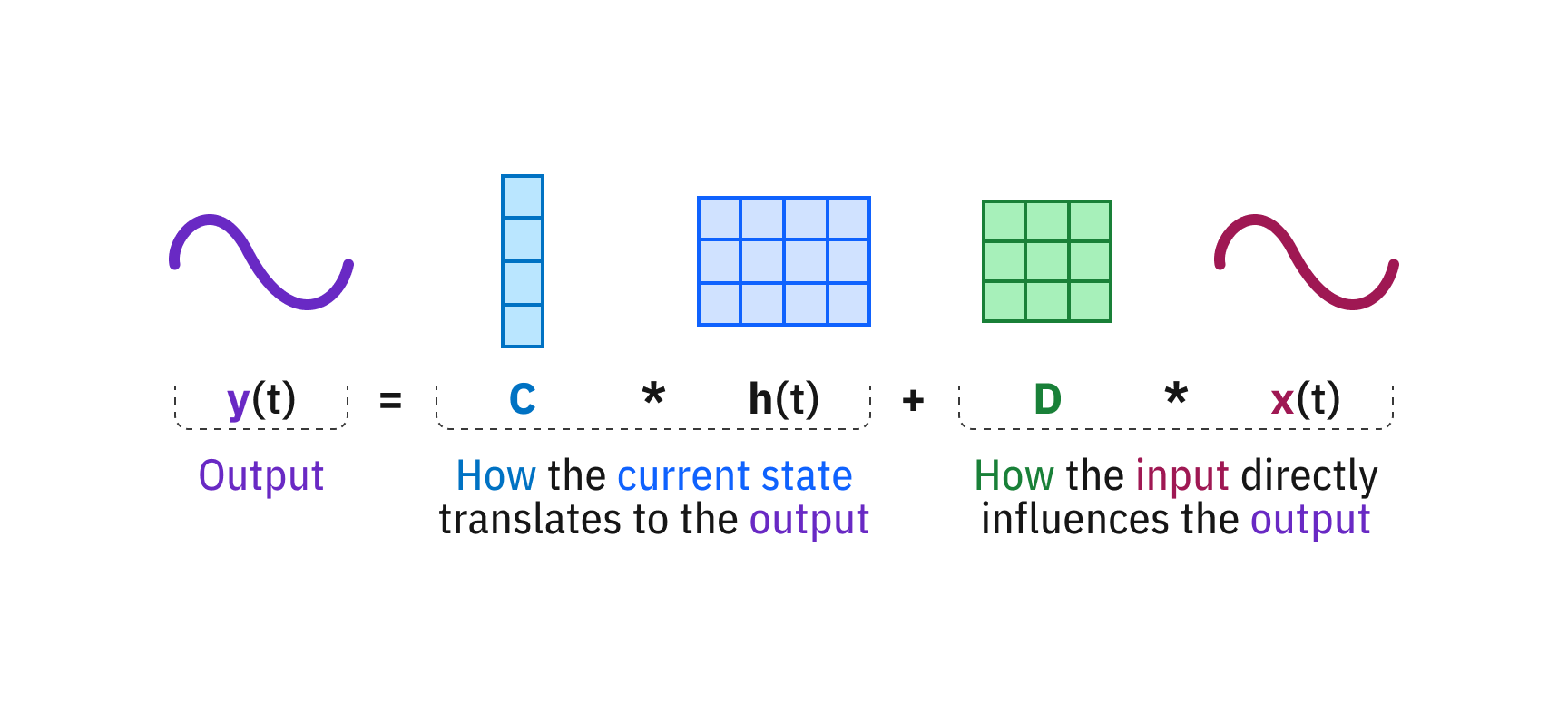
Mamba模型
从动力系统的角度来看,像 Mamba 这样的状态空间模型 (SSM) 具有 Transformer 所缺乏的理论优雅性:它们本质上是离散化的连续时间系统。
当我们使用Transformer来模拟电网时,我们实际上是将一个连续的物理过程(电流)强行转换成离散的语言结构(Token)。这就造成了“离散化鸿沟”。
相比之下,SSM 将输入序列映射到其他模型。通过微分方程 进入潜状态。这在数学上与控制网格的物理定律(例如,发电机惯性)同构。 如果吸引子是系统的“形状”,则隐藏状态在SSM中,是系统在该流形上的坐标。与Transformer中的检索不同,SSM中的循环状态是一个压缩的物理内存,它沿着流形的曲率不断演化。
为了完全重建复杂混沌系统的相空间,Takens 嵌入定理表明我们需要足够长的观测窗口来展开吸引子的拓扑结构。
所以,SSM 相较于基于注意力机制的模型具有明显的优势。它们的线性复杂度 使得它们能够吸收海量的历史序列,而不会受到记忆瓶颈的限制。 这意味着理论上,SSM 可以“看到”整个极限环或奇异吸引子的完整轨迹,而 Transformer 通常仅限于一个截断的局部窗口。 通过保持系统演化的长期记忆,SSM 可以更好地区分系统动力学中的暂时波动和结构性转变,原因很简单,因为它们“看到”了流形的更多历史信息。
阿喀琉斯之踵
然而,虽然 SSM 擅长模拟系统的内部惯性(自相关),但它们难以以物理上可解释的方式明确地模拟外部强迫(外部相关)。
用物理学的语言来说,电网是一个受迫动力系统:。
其中外部天气条件是影响因素。目前最先进的SSM模型通常将各个通道独立处理,和我们之前论述的一样,其存在缺点,想要做的更好,一个更深层次的物理约束是不可或缺的。
五、通用模型之终
时间序列预测的未来,不在于构建一个万能的 LLM,而在于构建物理感知的架构。
当我们放弃了“通用模型”的执念,开始尊重数据的物理属性,区分确定性与随机性,我们才能真正突破准确率的天花板。