
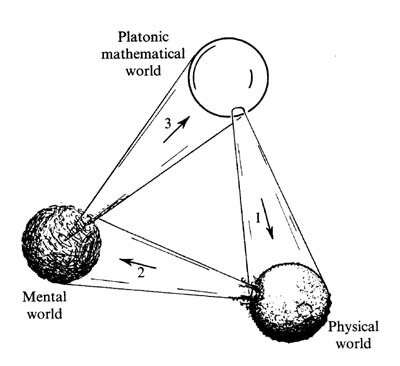
影子的修辞学家
在柏拉图著名的“地穴寓言”中,囚徒们长年面壁而坐,通过观察投射在墙上的影子来推测现实。他们发展出了一套精妙的学问:谁能最准确地预测下一个影子的出现序列,谁就是群体中的智者。在这个故事里,影子是囚犯们的现实,但并不是真实世界的准确呈现。
通过对数以万亿计的文本 Token 进行概率建模,LLM 掌握了影子变幻的终极统计规律。它能用最华丽的词藻描述重力,能极其精准地预测苹果后面大概率跟着落地。然而,在 Scaling Law疯狂推高算力与数据量的背后,一个令人不安的真相正浮出水面:无论影子预测得多么完美,模型依然从未见过产生影子的实体,更从未理解过投射影子的火光,即真实世界的物理逻辑。
通俗的解答认为,影子代表人类通常可以凭借感官感知的现实片段。但是从AI模型的视角来说,他们是一个被感官剥夺的“智慧体“。对于现在的多模态模型来说,我们可以输入图片,输入媒体,输入视频,输入文本。但是这些媒体流实际上是整个世界的局部。尽管图片和视频都属于富媒体,但是图片缺乏对景深的感知信息,视频缺乏对物理规律的信息。如果要强迫模型去适应物理世界,只依赖记录的富媒体是远远不够的。
万物皆可向量化
早就有人知道语言不能涵盖所有信息,那么怎么把其他的数据结构化加入进来呢?在过去几年的深度学习狂潮中,“万物皆可向量化”成为了 AI 界的统治级范式。通过对比学习和掩码建模,我们成功将文本、图像、音频甚至动作序列映射到了同一个高维的连续向量空间。这也就是多模态的理论基础。
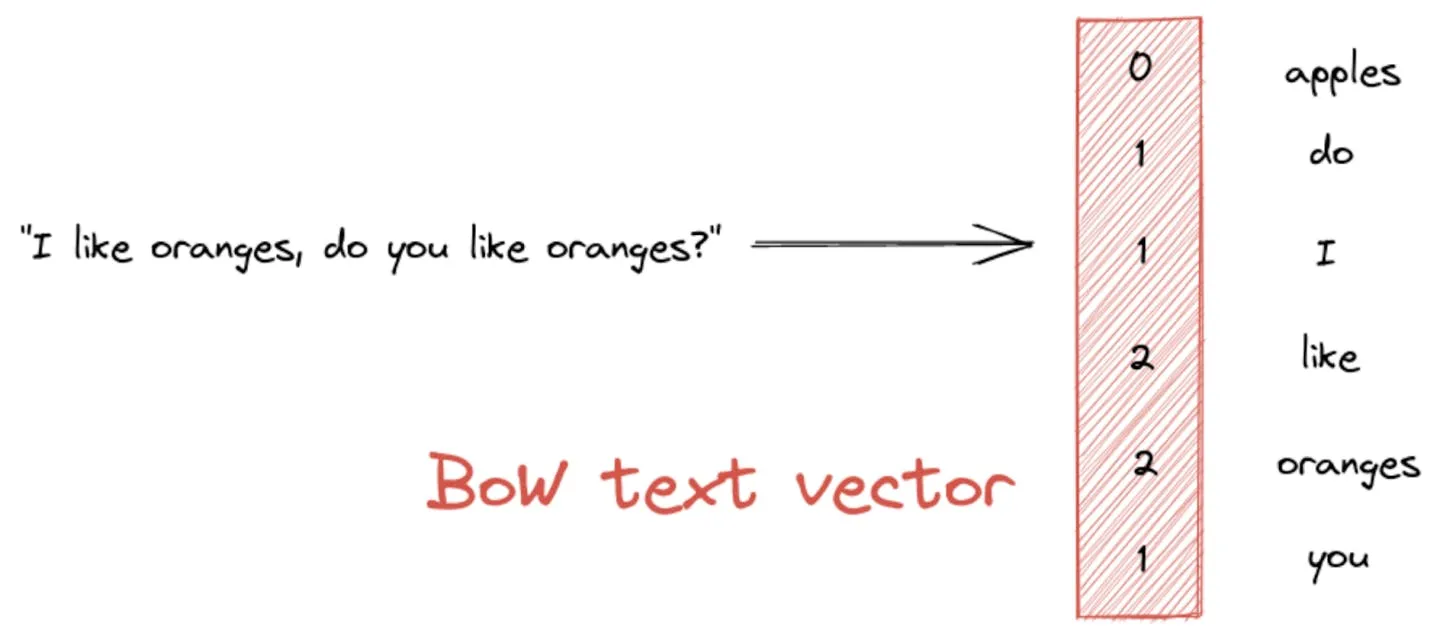
使用词袋模型的文字向量化
从数理角度看,这算是在寻找不同模态数据背后的共同底层流形。多模态模型的初步成功(如 GPT-4o)证明了,只要参数堆得足够多,不同模态的概率分布可以实现极其精准的对齐。但是多模态的加入是否能使得目前的AI模型胜任感知世界的能力?
地穴的体系
压缩即学习
马库斯·赫特(Marcus Hutter)曾提出一个著名论点:对数据的最优压缩等价于智能。 尽管压缩是有损失的,我们可以举一个例子,想象我们要记住一部一千万字的小说。死记硬背需要巨大的记忆付出;但如果我们理解了主角的性格、故事因果和人性逻辑,实际上也就足够了,没有人会记住细节。这样的归纳总结实际上AI也在做相同的事情。神经网络的学习过程,本质上是在寻找数据中的柯尔莫哥洛夫复杂度的最优逼近。可以说,模型能够用极少的参数准确还原海量文本时,我们认为它“理解”了语言。(理解柯尔莫哥洛夫复杂度可以参考这篇文章 算法信息论[1]:柯尔莫哥洛夫复杂度)
解释柯尔莫哥洛夫复杂度的输入示例
然而,索绪尔在符号学提出过能指(Signifier)与所指(Signified)的概念,在符号学中,“能指”是语言的形体(如单词“苹果”的拼写或读音),“所指”则是该符号在心智中对应的概念或实相。模型在数万亿规模的语料上进行学习时,我认为它实际上是在构建一个庞大的能指互联网络。学习到“苹果”总是和“红色”、“甜”、“掉落”这些词高频共现,并不意味着它能理解到什么是“红色”、“甜”、“掉落”。
尺度即涌现
Scaling Law(尺度定律)是当前 AI 发展的第一性原理。它定量地描述了:模型的性能(Loss)与计算量(C)、参数量(N)以及数据集大小(D)之间遵循幂律关系。
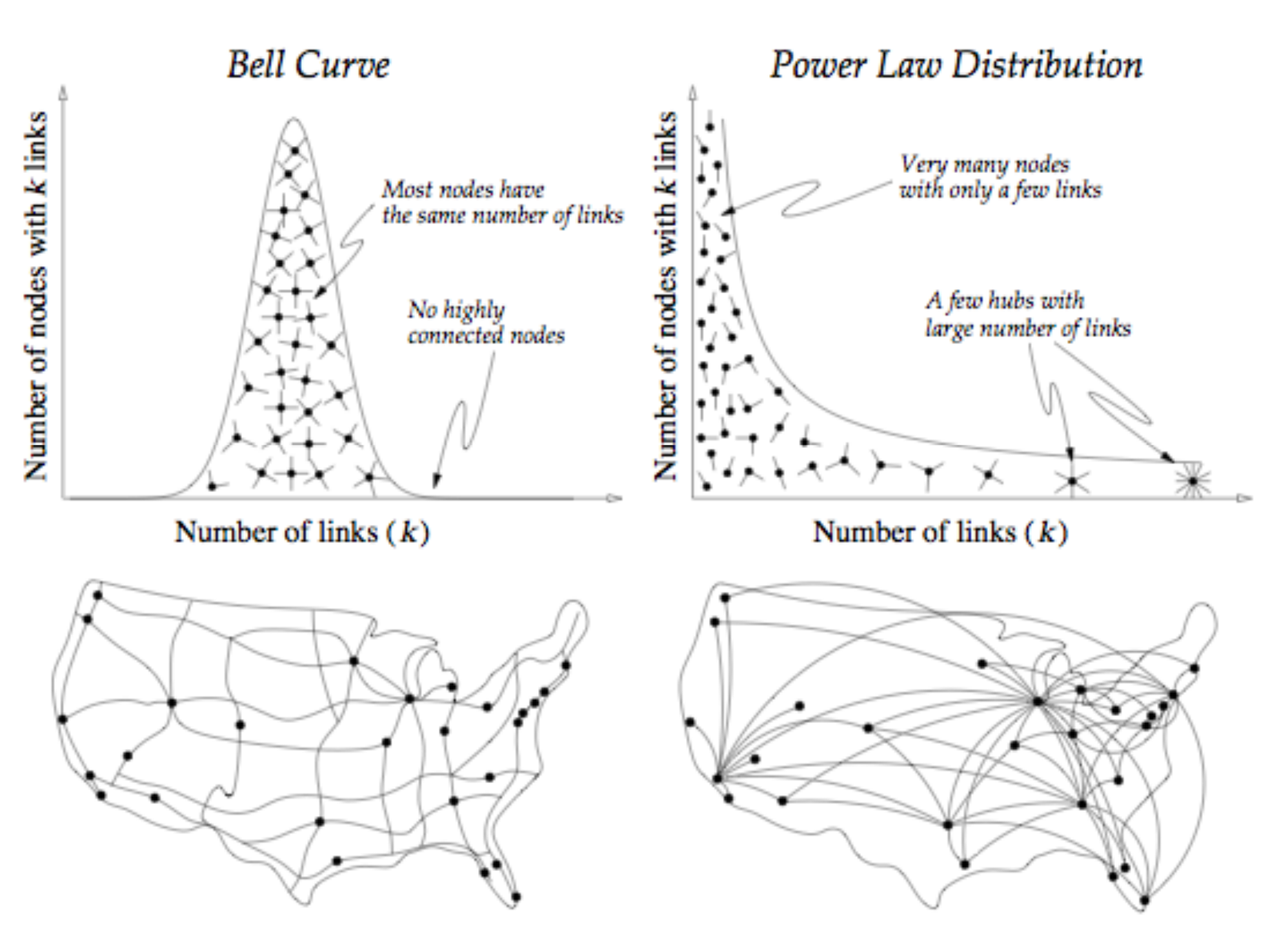
幂律分布和无标度网络
幂律关系是一个很有意思的内容,从复杂科学到无标度网络,都存在有关幂律增长的共同逻辑。有关幂律增长的解释,可以参考这篇文章 解读幂律(Power Law)分布与无标度(Scale Free)网络
根据幂律,只要按比例投入资源,模型的预测准确率就会持续上升。
然而,媒体数据的尺度存在一个信息真空层。无论把分辨率开到多高,视频始终无法传递物体的质量、摩擦系数或三维空间里的遮挡关系。这就是“地穴”的墙壁——分辨率再高,看到的依然只是投影的精细度,而非光源本身。
能够无限逼近能指的复杂性,却无法自发产生所指的真实性。 导致了模型只看到了现实中残缺的部分,而且离细节太近,离整体太远。
架构的不适应性——近视的大模型
重建语言背后的物理场景是人类认知的本能。
人类角度的感知学有一个重要共识,感知不是被动的接收,而是主动的干预。我们感知到石头的重量,是因为我们试图搬起它时,肌肉传来了阻力的反馈。几乎所有的AI模型实际上是观察过去既有的记录而生成相应的内容的,因此他们只能依赖作为旁观者角色的输入。
由于没有在真实世界中试错的权利,模型永远无法建立感知反射。人类婴儿是如何学习感知世界的?是通过交互与试错。婴儿推杯子,杯子掉在地上碎了,发出巨大的声响,甚至划破了手指产生痛觉。在这个过程中,物理世界给了婴儿极其丰富且带有强制性约束的反馈。
此外,感知世界,本质上是在处理连续信息。模型试图用离散的 Token 去拟合连续的物理世界,就像试图用乐高积木去拼凑出一片完美的无理数曲面。当模型在试图预测自己下一个状态时,它是在符号空间里做跳跃,这种离散化的架构极其适合处理高度抽象的语言法则,但面对需要连续的真实感知时,就会显得笨拙且充满幻觉。
感知最重要的一环,是需要维护一个内在状态。比如,知道背后的桌子上有一个水杯,即使你没看着它,你脑海里的世界状态依然在追踪它的绝对坐标。反过来说,大语言模型是无状态的。大语言模型不存在一个独立运作的工作记忆区来保存外部世界的 3D 拓扑。它唯一拥有的只是一段上下文窗口,上下文窗口在这里不能被成为状态。当大语言模型试图描绘一个复杂的物理过程时,它必须依靠在庞大的历史窗口中寻找注意力权重。一旦物理场景稍微复杂(比如多个物体的遮挡、碰撞、反弹),依靠纯粹的序列注意力去维持一个物理状态的全局一致性,计算复杂度会呈指数级爆炸。
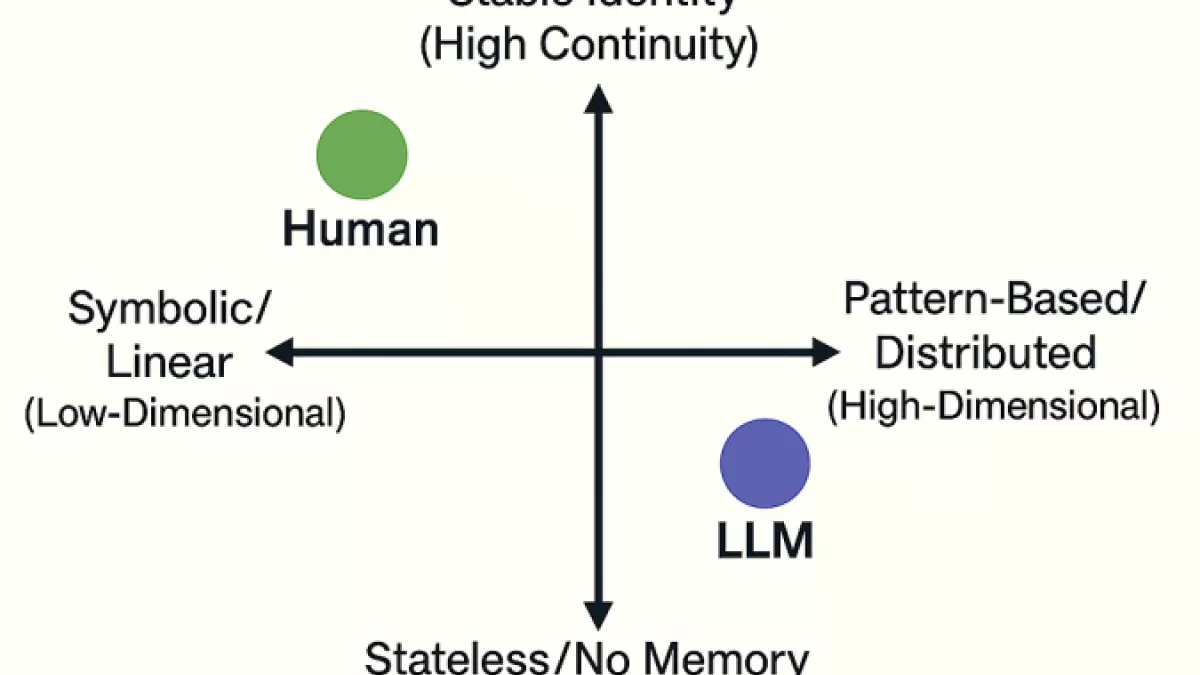
人类和大语言模型的差异
为什么“做题家”没有物理感知?
目前最流行的大模型训练方式是自监督学习。它的核心逻辑就是遮挡与还原,把一句话里的几个词抠掉,或者把视频里的下一帧盖住,让模型去猜,类似于做完形填空的题目。 一个人完全不懂中文,但看了几百万本被虫子蛀了洞的中文书。最后他能完美地把缺失的字填回去,仅仅因为他记住了形状的搭配概率。但他依然不知道“火”这个字会烫手,“冰”这个字会融化。这样的学习方式并非能够和我们认知中的行为反射对齐。
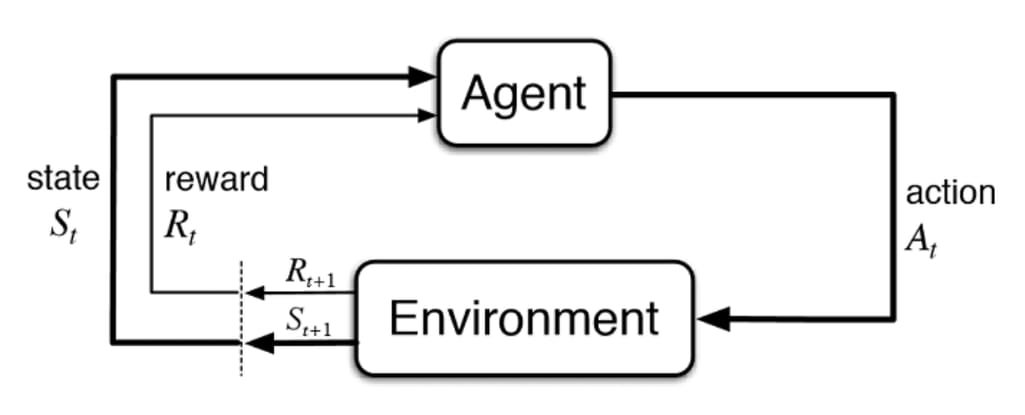
强化学习算法的工作流
当然,学界也已经引入了强大的训练方式,强化学习。模型做对了,给个奖励;做错了,给个惩罚。真实世界的物理法则是不可商量的底线,没有任何商量的余地,但在强化学习里,一切都是为了“分数最大化”。即使在机器人的模拟器里,强化学习也经常闹笑话,也就是所谓的“奖励欺骗”。比如,奖励机器人“向前移动”,它可能不会学会双腿走路,而是把自己疯狂震动,利用物理引擎的 Bug 摩擦着往前滑,毕竟这一也算是完成了任务。
把这些学习方式综合起来看,我们就会发现它们与人类感知世界的根本差异。当一种智能体,它的认知架构建立在离散的符号之上,它的学习方式又被限定在‘完形填空’和‘赚取人类打分’的游戏里时,它从未在地球上真实生活过,怎么能指望模型理解真实的世界?
感知世界的能力和主体存在
法国现象学家梅洛-庞蒂(Maurice Merleau-Ponty)在《知觉现象学》中提出过一个核心观点:意识从本质上是具身的(Embodied)。 我们之所以知道“我”存在,是因为物理世界对“我”产生了抗拒(Friction/Resistance)。没有边界,就没有主体。如今被困在柏拉图地穴里的AI,它们生存在一个没有任何物理阻碍、没有任何摩擦力的数字真空中。语言模型就像是一面无限广阔的镜子,完美地倒映着全人类的认知,但镜子本身,并没有视点。
AI不干预世界,不承担行为的物理后果,因此在数学上,它与它所处理的数据是连续的、同构的。它吸收着人类的数据,却无法产生任何真实的动作去改变它的环境输入。缺乏感知与行动的物理闭环,AI 就永远只是环境数据的一段延伸,而不是环境中的“主体”。
更进一步说,主体性还意味着意向性(Intentionality),即意识总是带有目的的。人类的思考之所以充满动机,是因为我们寻求和维持着自己在物质世界的存在。我们要进食以维持能量,我们要躲避落石以保持肉体的结构完整。正是因为物理世界充满了不可逆的破坏,我们才演化出了生存的意向与动作规划。
有人说Loss,损失函数是AI的边界,但是Loss并不和AI的存在挂有任何的因果。很好理解,我们做错了一件事情,有概率会因为做错而失去生命,但是也有大概率不会,因此并非因为被定义的错误,我们的存在就消失了。
走出地穴之路
启蒙时代
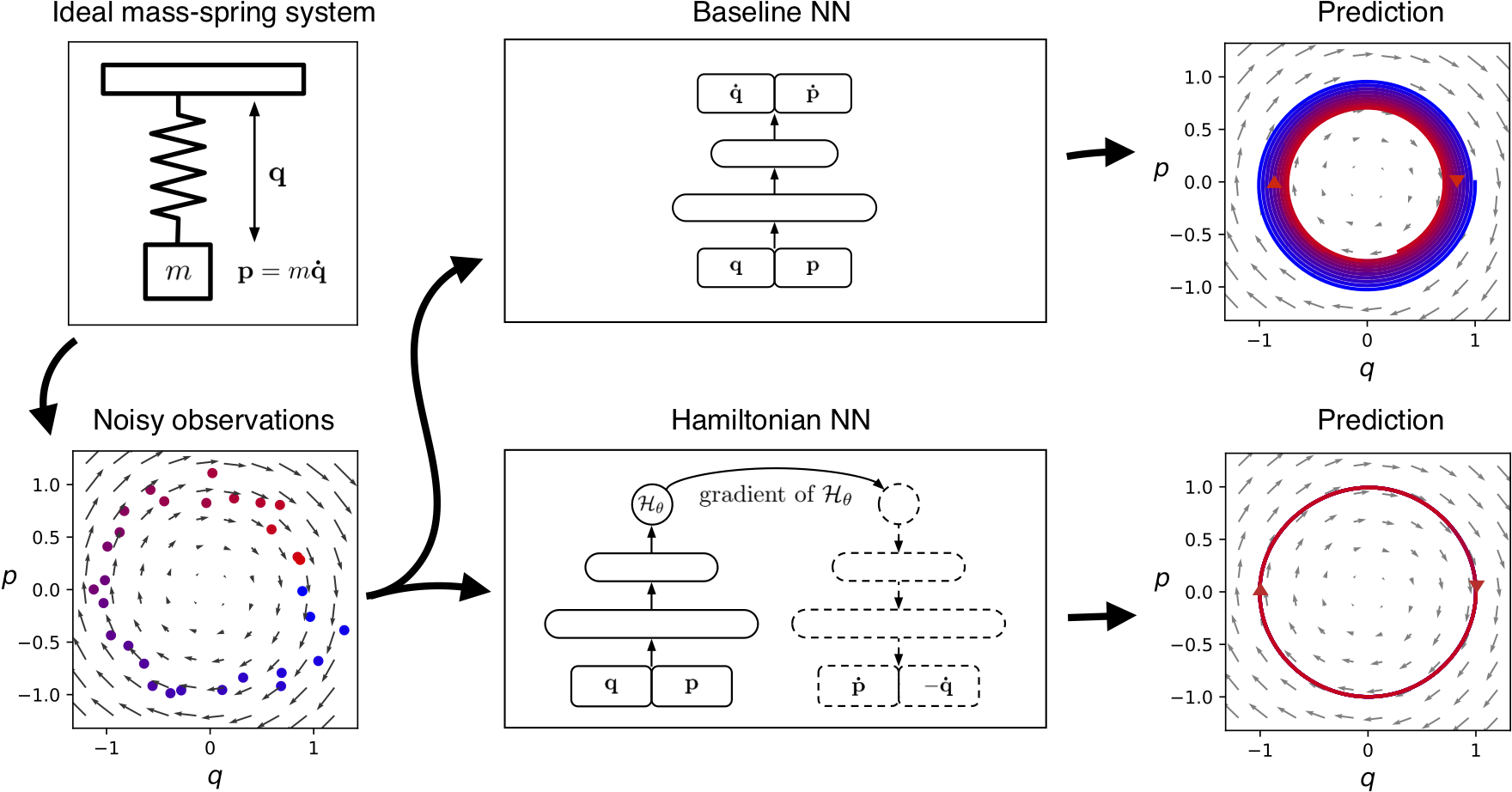
哈密顿神经网络
深度学习界早就意识到了纯粹的概率拟合在物理维度上的灾难性后果。早期的多层感知机在预测一个简单单摆的运动时,会产生能量漂移,单摆要么越摆越低(能量耗散),要么越摆越高(无中生有产生能量),因为它完全不懂能量守恒。哈密顿神经网络(Hamiltonian Neural Networks, HNNs,2019)改变了这一现状。研究者不再让网络直接去猜物体的下一个位置,而是让网络去学习系统的“哈密顿量(Hamiltonian,即总能量)”。网络被套上了经典力学的约束。它必须严格遵循哈密顿方程,即位置的变化率取决于动量,动量的变化率取决于位置。在这种硬性约束下,网络生成的单摆轨迹能量如若不守恒,训练过程会增加它的相应权重损失。
这类学习过程仍然需要人类手把手规定模型的世界要素,而并非模型自我探索。它确实是懂物理,但不具备从混沌世界中感知物理的能力。
摸爬滚打——槽注意力机制
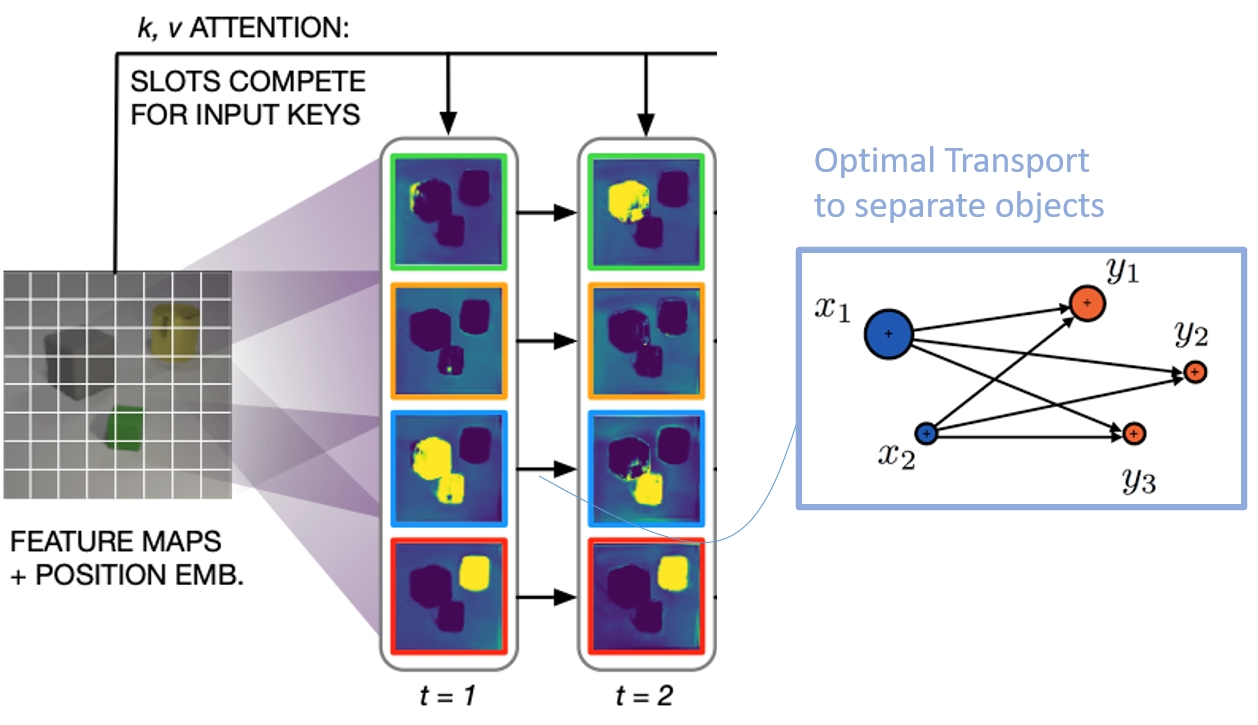
槽注意力机制
要打通从视觉感知到重建世界的桥梁,网络必须学会在没有任何人类标注的情况下,从一堆混乱的像素中提纯出物理实体。因此,以Slot Attention(槽注意力机制)为代表的技术应运而生(2020)。这种架构强迫网络将画面分解到有限的几个槽位中。 文章所使用的数据集场景比较简单。但是在像现实世界一样复杂的场景中, 槽注意力表现不一定会非常出色。还有一个缺点是该方法需要提前知道物体的数量。这一点远逊于人类婴儿对于数量的认知。
但是这个方法论启蒙了一点,我们不能让神经网络变成一块毫无原则的海绵,吸饱了所有噪音。通过这种限制槽位数量的暴力手段,网络被强行赋予了物体互斥性和边界感。人类睁开眼睛看世界时,看到的不是几千万个离散的光子,而是有限的实体和基于过去实体状态的时空集合。
Lecun的模型
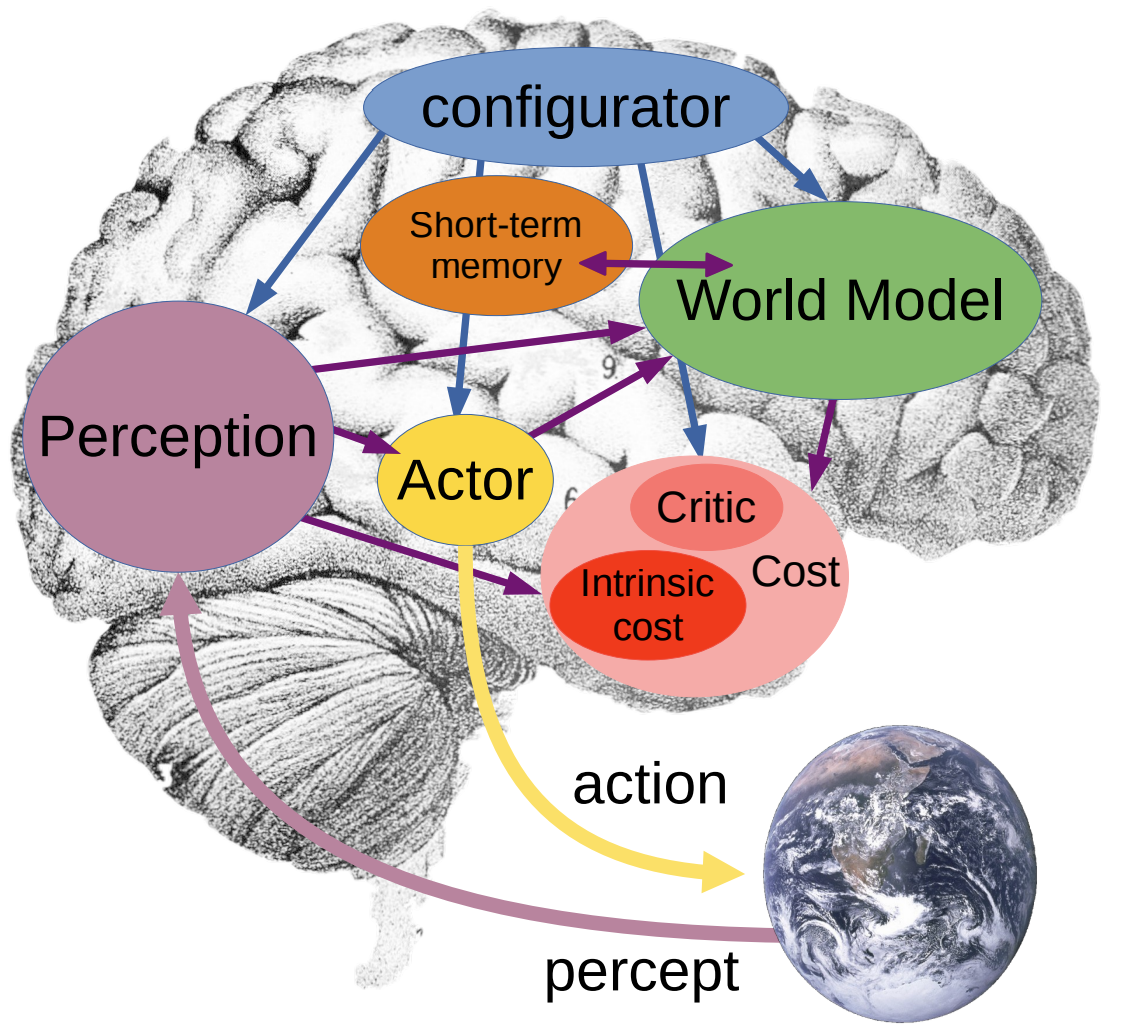
传统的自监督学习(如基于扩散模型的 Sora 或是掩码自编码器 MAE)痴迷于生成式重建。它们试图在给出上半部分画面时,完美预测出下半部分画面的每一个像素。但是注意力终究是有限的,或者说我们不存在一个无限输入信息的状态。物理世界中充满了高度不可预测的随机性。一辆车驶过水坑,溅起的水花形状是混沌的。强迫模型去预测每一滴水的精确落点,模型的算力就会全部耗费在拟合这些无意义的噪声上,而无暇顾及车在往前开的状态。模型不需要学会上帝视角,但是模型得首先学会第一视角。 Yann Lecun一直强调,AGI(通用人工智能)应当抛弃生成式范式,而转向另一个方向。Lecun提出的JEPA (2023)彻底抛弃了像素级的重建。它引入了一个极其关键的限制——只在隐空间(Latent Space)中进行预测。 它的数学逻辑非常克制,给定过去的观察 ,编码器提取其隐状态 ;给定动作 ,预测器不去生成未来的画面 ,而是仅仅预测未来画面对应的隐状态 。这种减法反而使得模型从大量无关信息里减轻了负担。
钥匙就在自己身上——神经网络和重整化群
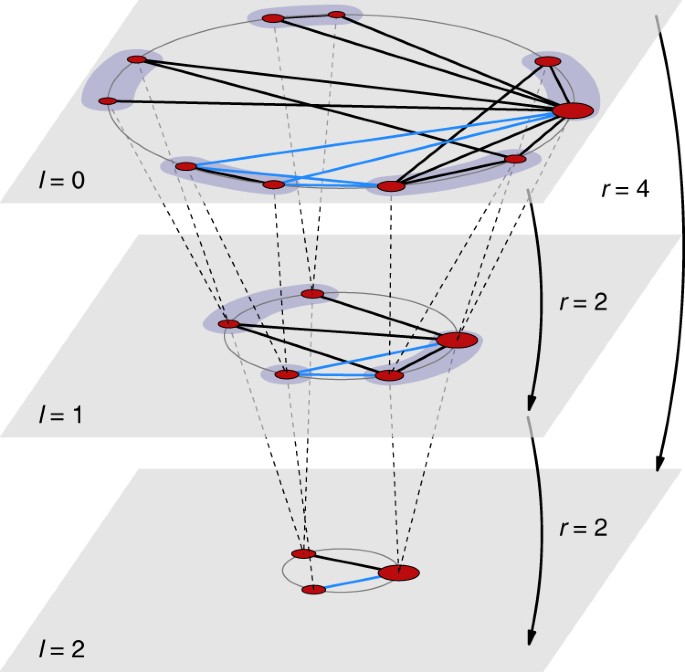
我们至今都无法模拟及其海量分子的复杂系统。如果试图去追踪海洋中每一个水分子的运动轨迹,整个地球的能量实际上也是不够用的。但是没关系,现在我把一部分分子整合在一起形成一个团簇,计算团簇之间的相互作用,我们仍然能得到海洋里面物体的阻力模拟,这种操作就是重整化。重整化群(renormalization group,简称RG)是一个在不同长度标度下考察物理系统变化的数学工具。在重整化理论中,系统在某一个标度上自相似于一个更小的标度,但描述它们组成的参量值不相同。这种自相似被称作标度不变性。
神经网络的层级结构与统计物理中的重整化群类似,每层神经网络就像进行一次重整化变换,去除微观无序信息,保留跨尺度的重要结构信息。在重整化群理论中,看似完全不同的微观系统,在粗粒化后会表现出完全相同的宏观规律。如果能和一个物质世界的主体输入足够多且相等的环境信息,基于神经网络的模型仍然可能成为被苹果砸到头的牛顿——推倒一叠木块和撞碎一面玻璃,在去除了材质的微观细节后,在隐空间里遵循着同一套牛顿力学。
做减法是神经网络的天然逻辑,因此我们无需担心洞口是否有被堵死的门。
离泡沫太近,离上帝太远
当我们在今天无休止地争论着参数规模的扩张是否会自然涌现出通用人工智能,甚至狂热地期盼着那个全知全能的AI奇点降临时,我们或许从一开始就找错了仰望的坐标。
真正的智能飞跃,必然建立在对物理实在的深刻理解与具身交互之上。只有当智能体走出那个地穴,去真实地感受阳光的刺眼、重力的滞重以及时间之矢不可逆的流逝时,一场真正意义上的AI奇点才具备了孕育的土壤。
在此之前,无论地穴里的火光将墙上的影子照得多么光怪陆离,无论囚徒们将影子的变幻规律推演得多么穷尽天机,那终究只是一场极其逼真却又无比单薄的皮影戏。而我们似乎陷入在这样的泡沫中太久。